
Evaluators
We've added Evaluators to Humanloop in beta!
Evaluators allow you to quantitatively define what constitutes a good or bad output from your models. Once set up, you can configure an Evaluators to run automatically across all new datapoints as they appear in your project; or, you can simply run it manually on selected datapoints from the Data tab.
We're going to be adding lots more functionality to this feature in the coming weeks, so check back for more!
Create an Evaluator
If you've been given access to the feature, you'll see a new Evaluations tab in the Humanloop app. To create your first evaluation function, select + New Evaluator. In the dialog, you'll be presented with a library of example Evaluators, or you can start from scratch.
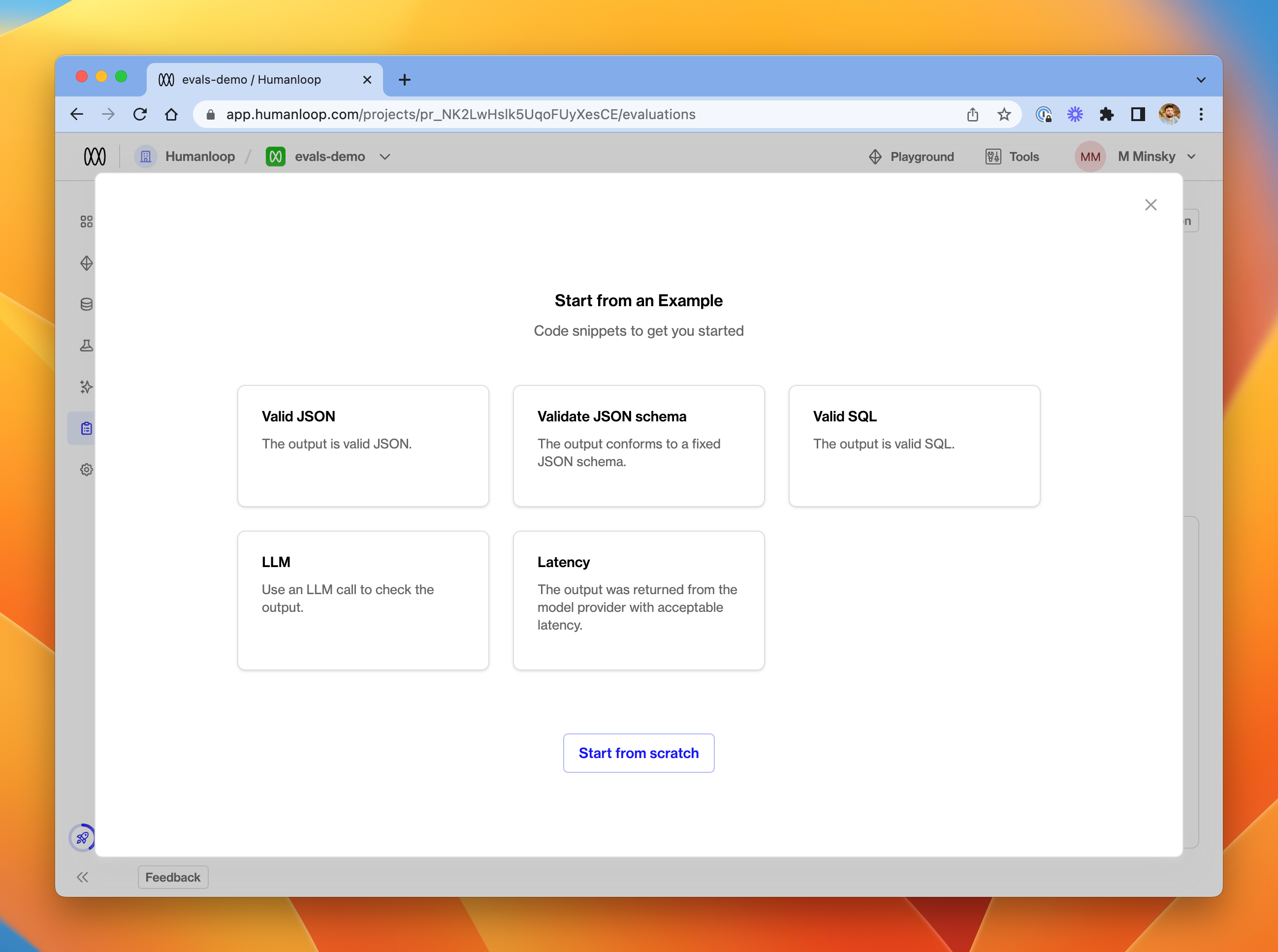
We offer a library of example Evaluators to get you started.
We'll pick Valid JSON for this guide.
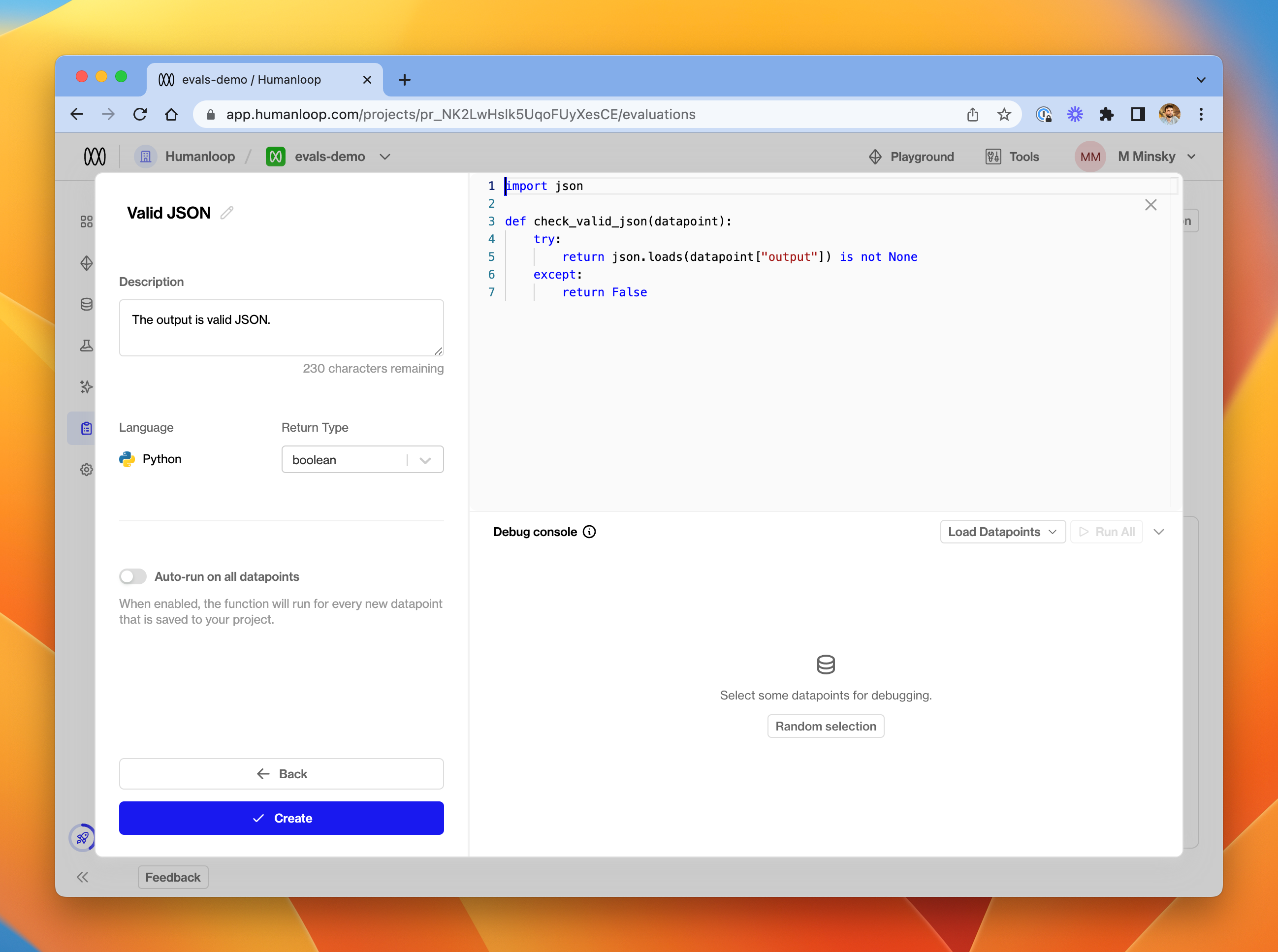
Evaluator editor.
In the editor, provide details of your function's name, description and return type. In the code editor, you can provide a function which accepts a datapoint argument and should return a value of the chosen type.
Currently, the available return types for an Evaluators are number and boolean. You should ensure that your function returns the expected data type - an error will be raised at runtime if not.
The Datapoint argument
Datapoint argumentThe datapoint passed into your function will be a Python dict with the following structure.
{
"id":"data_XXXX", # Datapoint id
"model_config": {...}, # Model config used to generate the datapoint
"inputs": {...}, # Model inputs (interpolated into the prompt)
"output": "...", # Generated output from the model
"provider_latency": 0.6, # Provider latency in seconds
"metadata": {...}, # Additional metadata attached to the logged datapoint
"created_at": "...", # Creation timestamp
"feedback": [...] # Array of feedback provided on the datapoint
}
To inspect datapoint dictionaries in more detail, click Random selection in the debug console at the bottom of the window. This will load a random set of five datapoints from your project, exactly as they will be passed into the Evaluation Function.
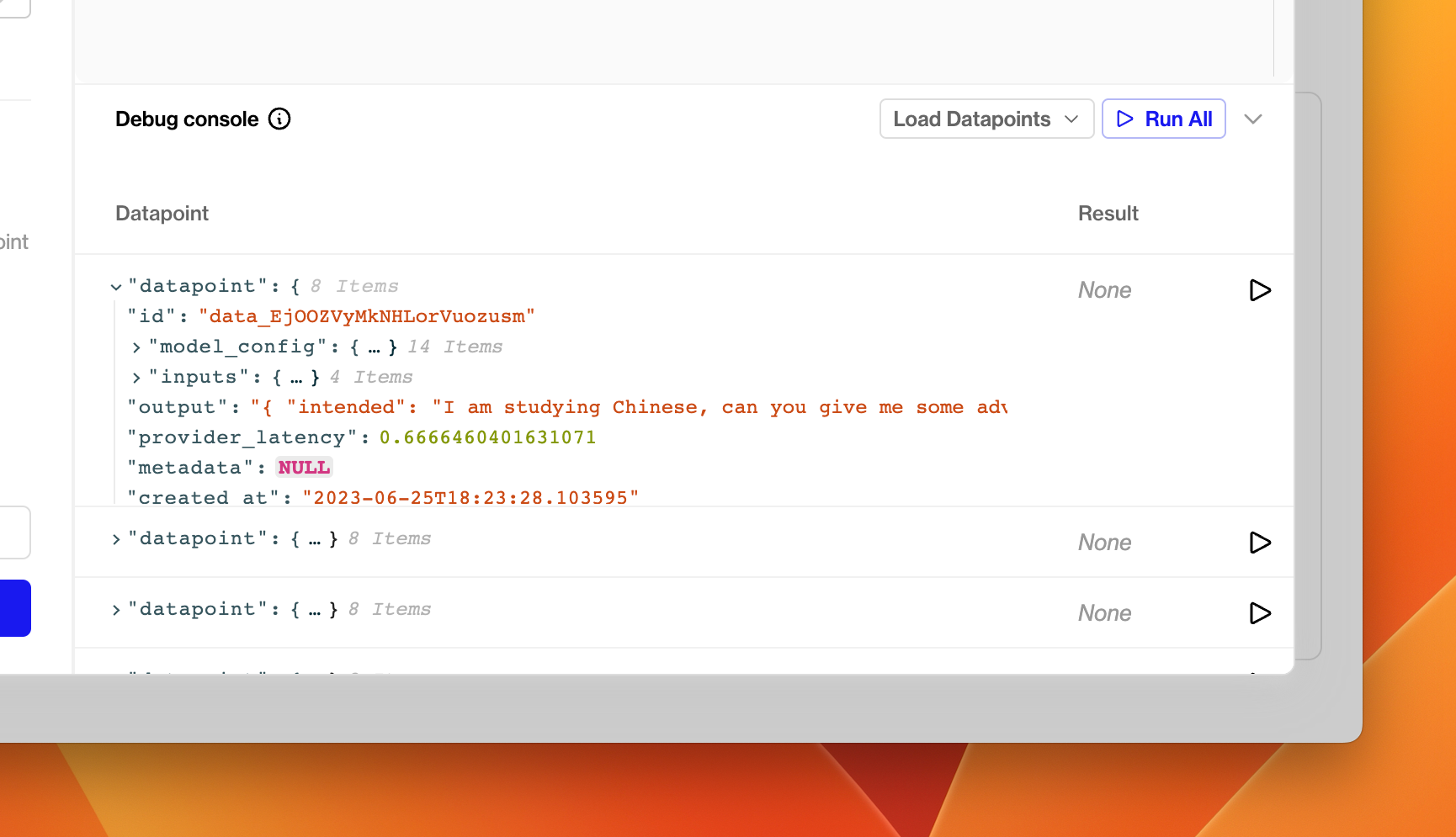
The debug console - load datapoints to inspect the argument passed into Evaluators.
For this demo, we've created a prompt which asks the model to produce valid JSON as its output. The Evaluator uses a simple json.loads call to determine whether the output is validly formed JSON - if this call raises an exception, it means that the output is not valid JSON, and we return False.
import json
def check_valid_json(datapoint):
try:
return json.loads(datapoint["output"]) is not None
except:
return False
Debugging
Once you have drafted a Python function, try clicking the run button next to one of the debug datapoints in the debug console. You should shortly see the result of executing your function on that datapoint in the table.
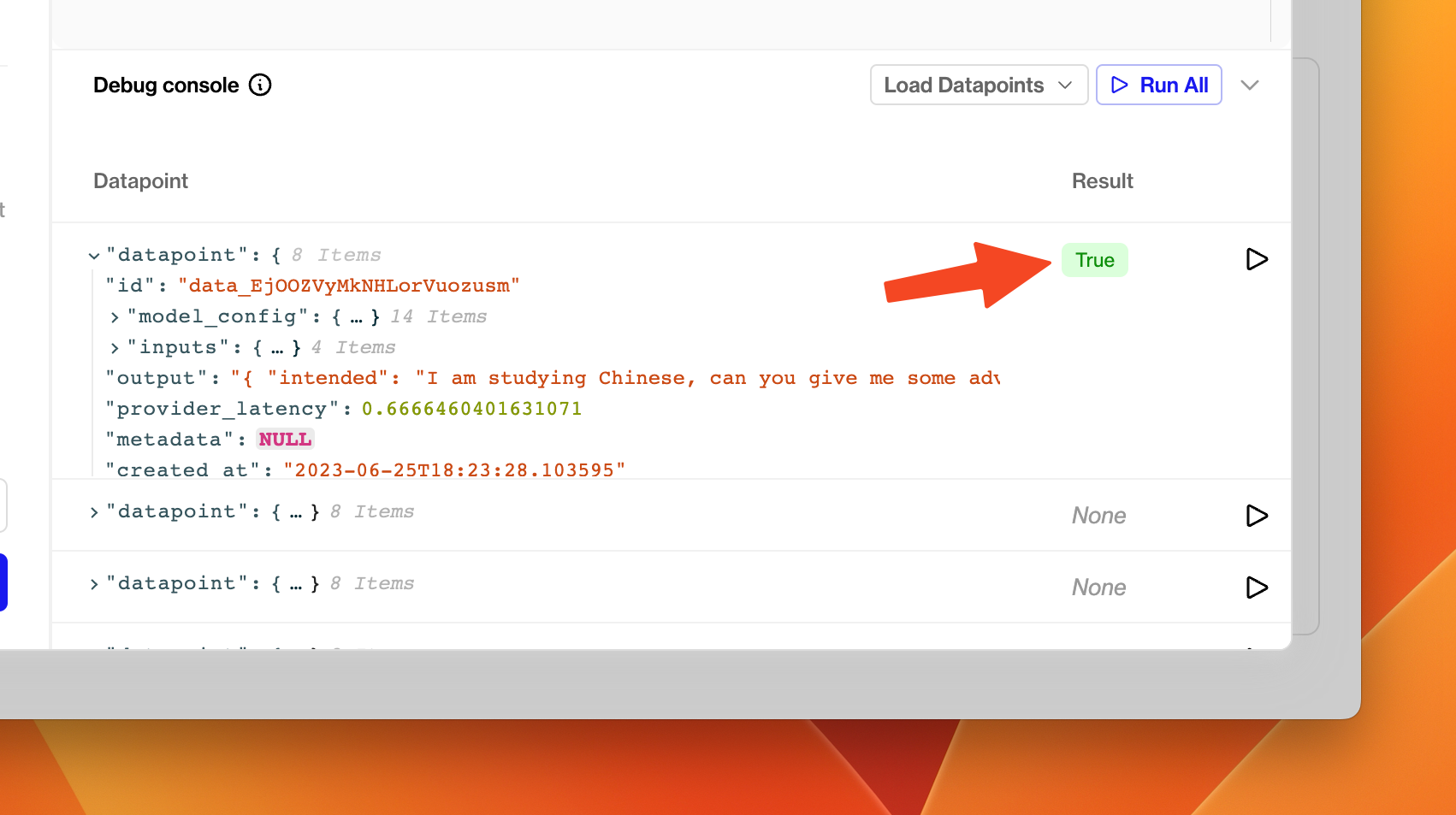
A True result from executing the Valid JSON Evaluators on the datapoint.
If your Evaluator misbehaves, either by being invalid Python code, raising an unhandled exception or returning the wrong type, an error will appear in the result column. You can hover this error to see more details about what went wrong - the exception string is displayed in the tooltip.
Once you're happy with your Evaluator, click Create in the bottom left of the dialog.
Activate / Deactivate an Evaluator
Your Evaluators are available across all your projects. When you visit the Evaluations tab from a specific project, you'll see all Evaluators available in your organisation.
Each Evaluator has a toggle. If you toggle the Evaluator on, it will run on every new datapoint that gets logged to that project. (Switch to another project and you'll see that the Evaluator is not yet toggled on if you haven't chosen to do so).
You can deactivate an Evaluator for a project by toggling it back off at any time.
Aggregations and Graphs
At the top of the Dashboard tab, you'll see new charts for each activated Evaluation Function. These display aggregated Evaluation results through time for datapoints in the project.
At the bottom of the Dashboard tab is a table of all the model configs in your project. That table will display a column for each activated Evaluator in the project. The data displayed in this column is an aggregation of all the Evaluation Results (by model config) for each Evaluator. This allows you to assess the relative performance of your models.
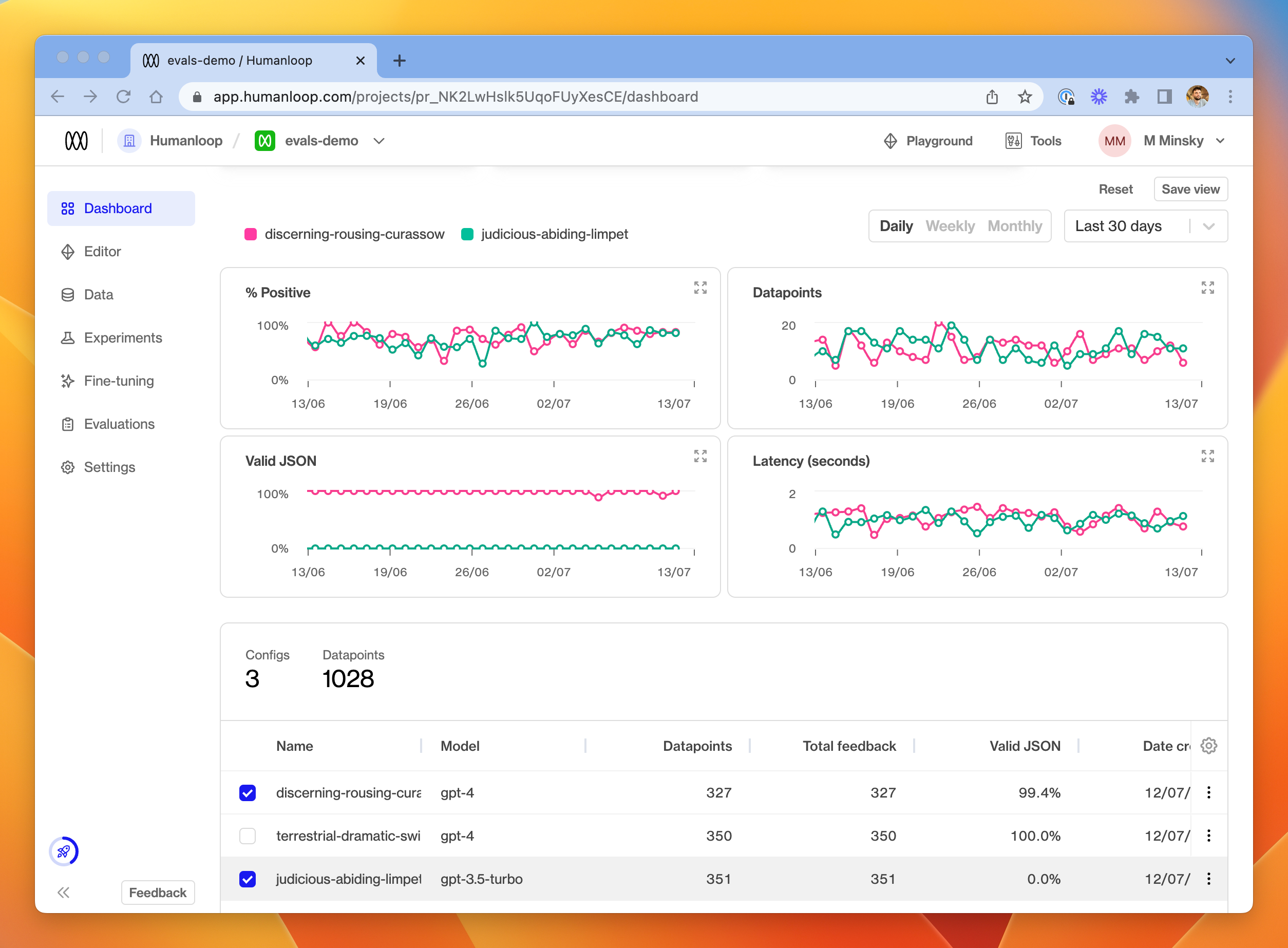
Evaluation Results through time, by model config. In this example, one of the model configs is not producing Valid JSON outputs, while the other is about 99% of the time.
Aggregation
For the purposes of both the charts and the model configs table, aggregations work as follows for the different return types of Evaluators:
Boolean: percentage returningTrueof the total number of evaluated datapointsNumber: average value across all evaluated datapoints
Data logs
In the Data tab, you'll also see that a column is visible for each activated Evaluator, indicating the result of running the function on each datapoint.
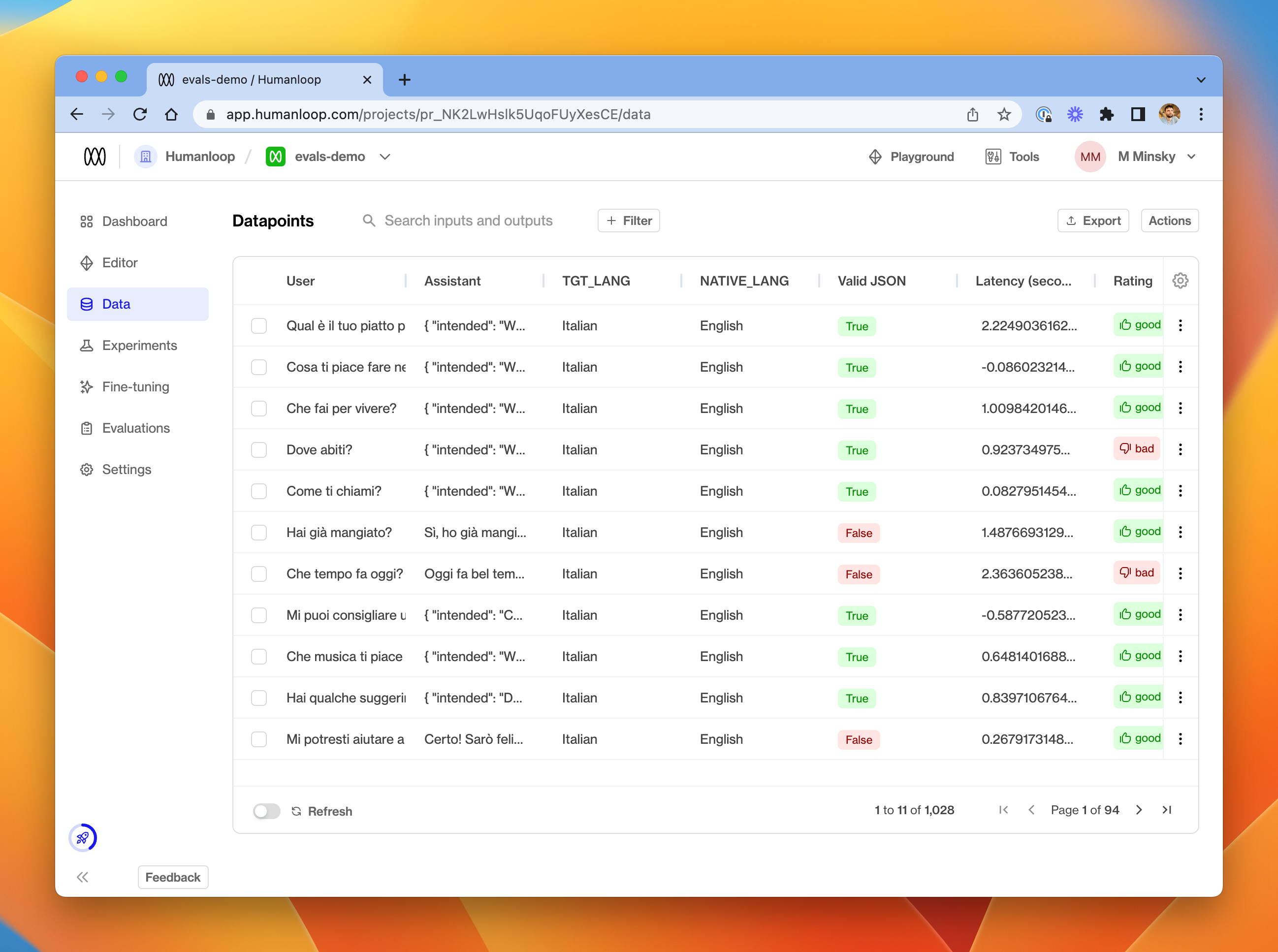
The Data tab for a project, showing the Valid JSON Evaluation Results for a set of datapoints.
From this tab, you can choose to re-run an Evaluator on a selection of datapoints. Either use the menu at the far right of a single datapoint, or select multiple datapoints and choose Run evals from the Actions menu in the top right.
Available Modules
The following Python modules are available to be imported in your Evaluation Function:
mathrandomdatetimejson(useful for validating JSON grammar as per the example above)jsonschema(useful for more fine-grained validation of JSON output - see the in-app example)sqlglot(useful for validating SQL query grammar)requests(useful to make further LLM calls as part of your evaluation - see the in-app example for a suggestion of how to get started).
Let us know if you would like to see more modules available.f